Ollama
Read Frog can leverage a locally deployed Ollama server to achieve offline AI translation capabilities,completely free to use powerful large language AI models
What is Ollama Server?
Ollama server is a lightweight, open-source AI model runtime platform that allows users to easily deploy various large language models (LLMs) and AI models locally without complex configuration. It acts as an "AI model manager," simplifying the tedious processes of model downloading, configuration, and runtime into just a few commands—making it accessible even for AI deployment beginners.
Ollama Local Deployment Tutorial
Download the Installer
You can download the installer from ollama.ai.
Configure Ollama's Cross-Origin Support
Please set the following environment variables:
-
Allow cross-origin access:
OLLAMA_ORIGINS=*macOS / Linux:
echo 'export OLLAMA_ORIGINS=*' >> ~/.zshrc source ~/.zshrcWindows (PowerShell in Administrator mode):
[System.Environment]::SetEnvironmentVariable('OLLAMA_ORIGINS', '*', 'User')After setting the environment variable, if you previously started the Ollama service, please close it first and then restart the
ollama servecommand. If you haven't started it yet, you can ignore this step. -
API service listening address:
OLLAMA_HOST=127.0.0.1:11434(This is the default address and can be left unchanged, but you can modify it based on your needs)
Common Ollama Commands
1. Check Ollama Version and Start the Server
ollama version
ollama serveUse these commands to check the currently installed Ollama version, confirm successful installation, view version details, and start the Ollama server.
2. Find Available Models and Install
You can find available models from ollama.ai and install them.
ollama pull [model-name]For example, to install the gemma3:4b model:
ollama pull gemma3:4b3. List Downloaded Models
ollama listThis command displays all locally downloaded models, including names, sizes, and creation times, to help users manage local model resources.
4. Start the Service
ollama serve5. Configure Ollama Provider in the Extension
In the extension settings, configure the Ollama provider and select a model.
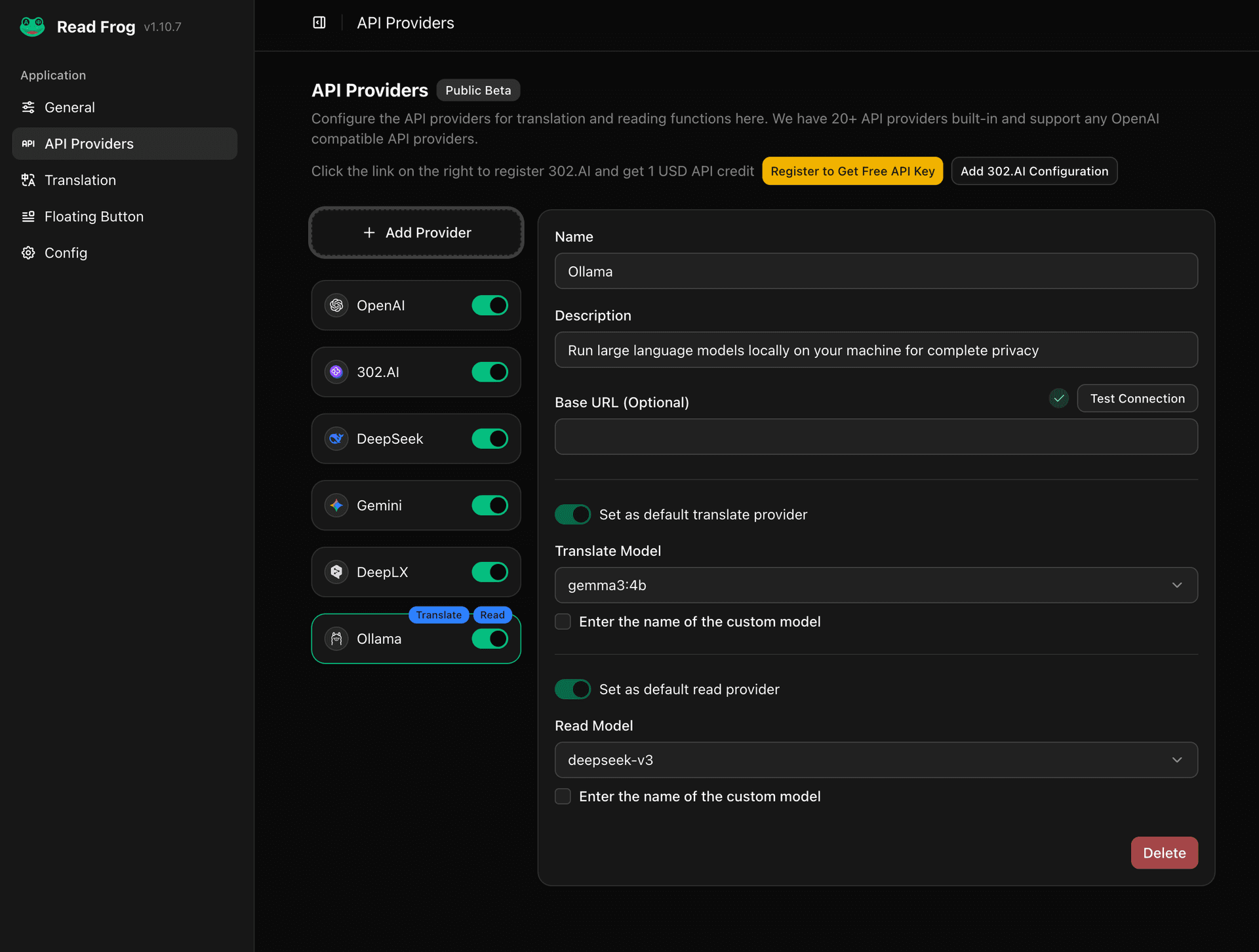
If you did not change the default address, you can leave baseURL blank or set it to http://127.0.0.1:11434/api.
If you changed the default address, you need to set the baseURL to the address you changed.
{
"baseURL": "http://127.0.0.1:XXXXX/api"
}You can click the "Test Connection" button to verify if the connection is successful.
6. Notes
- Do not start Ollama Chat graphical client, it will compete with
ollama servefor the port. - When configuring the Ollama provider in the extension, the baseURL defaults to
http://127.0.0.1:11434, if yourOLLAMA_HOSTis this address, you can leave it unchanged.
Troubleshooting
Windows: 403 Error When Connecting to Ollama
If you encounter a 403 error when the extension tries to connect to Ollama on Windows, it may be caused by running PowerShell (or the terminal) with administrator privileges. The elevated permissions can prevent the extension from properly accessing the Ollama service.
Solution: Close the administrator PowerShell and restart ollama serve in a regular (non-administrator) PowerShell window.