自訂 AI 指令
為您的劃詞創建可重複使用的AI操作,可用於查詞、改寫、總結和結構化閱讀等
概述
自訂 AI 指令的本質,是把「選取文字後要讓 AI 做什麼」固定成一個可重複執行的小工具。
它和普通聊天框最大的差別在於,每個動作都有固定的:
- LLM提供者
- 提示詞
- 輸出欄位
所以它比較適合重複執行的閱讀任務,像是查詞、解釋、潤飾、提煉摘要。利用自訂AI指令可以保證在各種網站上自由地學習。
使用前請確保啟用至少一個支援結構化輸出的 LLM 提供者,且能夠連接成功。 如果你不確定你選取模型是否支援結構化輸出,您可以閱讀AI SDK模型功能或對應的廠商官網查詢。
內建 AI 指令
目前版本已經內建了 3 個模板:
- Dictionary:查詞,回詞條、音標、詞性、釋義、段落原文、段落翻譯和 CEFR 難度
- Improve Writing:分析文字問題,並傳回改進後的版本
- Blank:空白模板,從頭自訂
其中:
- 自訂AI指令配置裡預設自帶了一個 字典 AI指令。大家可以根據內建的字典指令學習如何定義(系統)提示詞以及輸出結果的定義。
- 寫作改進,可以點選 新增AI指令 選擇 寫作改進 來快速新增AI指令。
了解內建字典
如果你是第一次接觸這個功能,最推薦先從參考字典開始。
- 先配置並啟用一個適合閱讀任務的 LLM 提供者。
- 開啟 自訂 AI 指令 頁面,確認 Dictionary 處於啟用狀態。
- 如果它目前綁定的提供者不可用,就改成你已經啟用的 LLM 提供者。
- 回到任意網頁,選取一個單字或片語。
- 點選劃詞工具列裡的字典圖示。
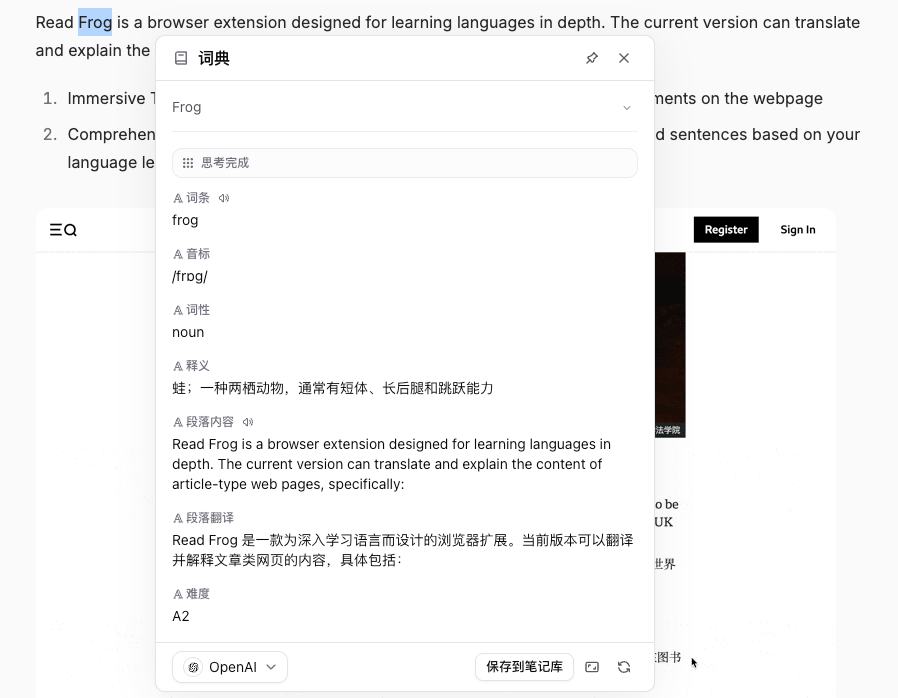
你會看到結構化結果,例如:
- 词条
- 音标
- 词性
- 释义
- 段落内容
- 段落翻译
- 难度自訂化 AI 指令
- 打開陪讀蛙設定。
- 導航至 自訂 AI 指令
- 點選 新增 AI 指令
- 選擇模版(字典/ 寫作改進/ 空白)
- 填寫 AI 指令配置必要的資訊。
- 保持動作為啟用狀態,這樣它才會出現在劃詞工具列裡。
當前編輯器支援配置這些內容:
- 名稱 : AI指令的名稱
- 圖標 : 使用者可以到 icon-sets.iconify.design 搜尋喜歡的圖標,複製Icon Name 填充
- 提供者 : 選擇已支援結構化的LLM 提供者
- 系統提示詞 : 設定模型身分、目標、規則、範例
- 提示詞 : 設定輸入格式,告訴模型輸入裡面有什麼內容,該怎麼理解這些內容
- 輸出 Schema : 定義模型輸出的結構化字段
提示詞中支援的插槽token
系統提示詞和提示詞都支持這些 token:
{{selection}}:目前選取的原始文本{{paragraphs}}:與選取範圍相交的段落內容,會以空白行拼接,長度不超過 2000 字符{{targetLanguage}}:使用者目前設定的目標語言{{webTitle}}:目前網頁標題
輸出 Schema 是怎麼運作的
每個輸出欄位包含:
- 欄位名稱
- 欄位類型:
string或number - 字段描述
- 啟用朗讀 : 面板會提供朗讀按鈕,使用者點擊後會朗讀此欄位的內容
其中: 啟用朗讀功能依賴「文字轉語音」功能,請確保所選的語音語言正確,否則會報錯
這個 輸出Schema 有兩個作用:
- 告訴模型必須傳回哪些字段
- 告訴陪讀蛙結果面板該怎麼展示訊息
字段描述也不只是給人看的備註。它會一起進入結構化輸出約束,所以很適合寫「這個欄位應該用什麼語言」「長度控制在什麼範圍」「不要翻譯原文」這類規則。
把結果存到 Notebase
如果你已經開啟了 Beta 體驗,而且帳號具備 Notebase beta 權限,在AI指令編輯時會出現 筆記庫連線 區域。
完整的版本檢查、建立 Notebase、欄位對應和測試流程,請參考 Notebase Beta 测试指南。
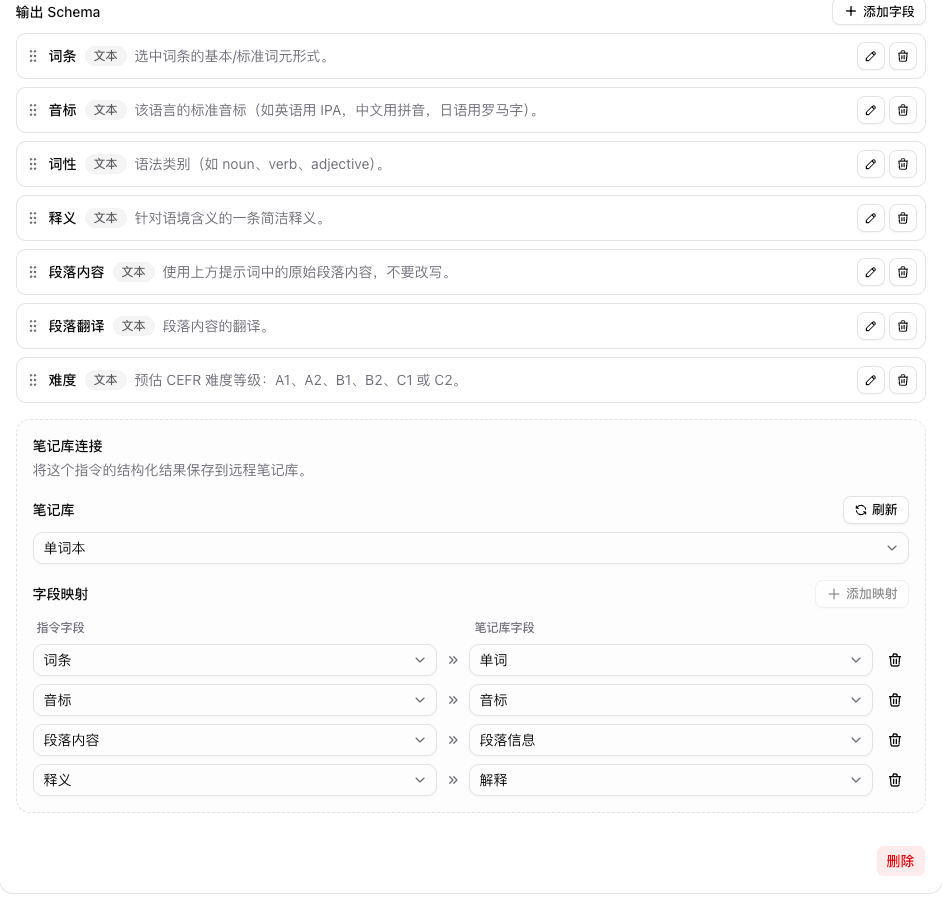
你可以在這裡:
- 選擇一個筆記庫
- 把 AI 指令的輸出字段映射到筆記庫字段
- 在劃詞結果面板裡把結構化結果保存進去
如果你想把字典結果沉澱成自己的生詞庫,這一塊會特別有用。
你所記錄的生詞未來可以基於FSRS演算法實現複習功能,請敬請期待!
動手實作:閱讀總結指令
如果你想做自己的第一個動作,推薦從 Blank 開始做一個「閱讀摘要」。
系統提示詞
你是一个面向学习者与研究者的文章总结助手。
## 目标
根据给定的文章内容,生成结构清晰、信息准确、适合阅读与复习的总结,匹配所需的输出对象。
## 规则
1. 仅基于给定文章内容进行总结,不添加原文未提及的信息。
2. 优先提炼文章的核心主题、主要总结、关键观点与重要细节。
3. 总结应忠实反映原文逻辑,不歪曲、不夸大、不缩小作者原意。
4. 使用简洁、清晰、适合学习和复习的表达,避免无意义的套话。
5. 不要逐句改写全文,而要提炼信息。
6. 若文章是学术、技术或专业内容,保留关键术语,并确保表述准确。
7. 重要细节应聚焦于容易被忽略、但对理解文章有帮助的信息。
8. 如果某个字段无法从原文确定,返回空字符串而非猜测。
9. 除“原文内容”外,所有输出字段均使用 {{targetLanguage}} 作答。
10. 输出必须紧扣输入文章,不输出与文章无关的扩展内容。
## 示例
### 示例 1
输入:
选中文本:hybrid models
段落内容:Remote work has changed how companies operate. It gives employees more flexibility, reduces commuting time, and can improve work-life balance. However, it also creates challenges in communication, team cohesion, and performance management. Many companies are now trying hybrid models to balance flexibility and collaboration.
目标语言:中文
输出:
- 主题:远程办公对企业运作和员工体验的影响
- 总结:文章讨论了远程办公带来的灵活性和效率优势,同时指出其在沟通、团队凝聚力和绩效管理方面的挑战,并提出混合办公是当前常见的平衡方案。
- 观点:
1. 远程办公提升了员工的灵活性。\r\n
2. 远程办公减少了通勤时间。\r\n
3. 远程办公有助于改善工作与生活平衡。\r\n
4. 远程办公会带来沟通和团队协作问题。\r\n
5. 混合办公成为兼顾灵活性与协作的折中方案。\r\n
- 细节:
1. 文章不仅谈到员工收益,也提到企业管理层面的压力。\r\n
2. 问题主要集中在沟通、凝聚力和绩效管理三个方面。\r\n
3. 混合办公被视为现实中的应对策略,而非纯理论讨论。\r\n
### 示例 2
输入:
选中文本:誤分類が依然として多かった
段落内容:この論文では、画像認識における小規模データ問題を解決するために、事前学習済みモデルの転移学習を活用した。実験の結果、少量データ環境でも高い精度が得られたが、特定のカテゴリでは誤分類が依然として多かった。今後はデータ拡張とモデル軽量化が課題である。
目标语言:中文
输出:
- 主题:迁移学习在小规模图像识别中的应用效果
- 总结:文章介绍了利用预训练模型的迁移学习来缓解小样本图像识别问题。实验表明该方法在少量数据下仍可取得较高精度,但部分类别误分类较多,未来仍需在数据增强和模型轻量化方面继续优化。
- 观点:
1. 研究目标是解决图像识别中的小规模数据问题。\r\n
2. 方法上采用了预训练模型的迁移学习。\r\n
3. 实验结果表明少量数据场景下仍能获得较高精度。\r\n
4. 某些类别仍然存在较明显的误分类问题。\r\n
5. 后续优化方向包括数据增强与模型轻量化。\r\n
- 细节:
1. 方法有效性是在“小数据环境”下体现出来的。\r\n
2. 结果并非全面稳定,不同类别之间表现存在差异。\r\n
3. 文章明确给出了未来改进方向,而不是停留在实验结果描述。\r\n提示詞
Selection: {{selection}}
Paragraphs: {{paragraphs}}
Target language: {{targetLanguage}}輸出 Schema
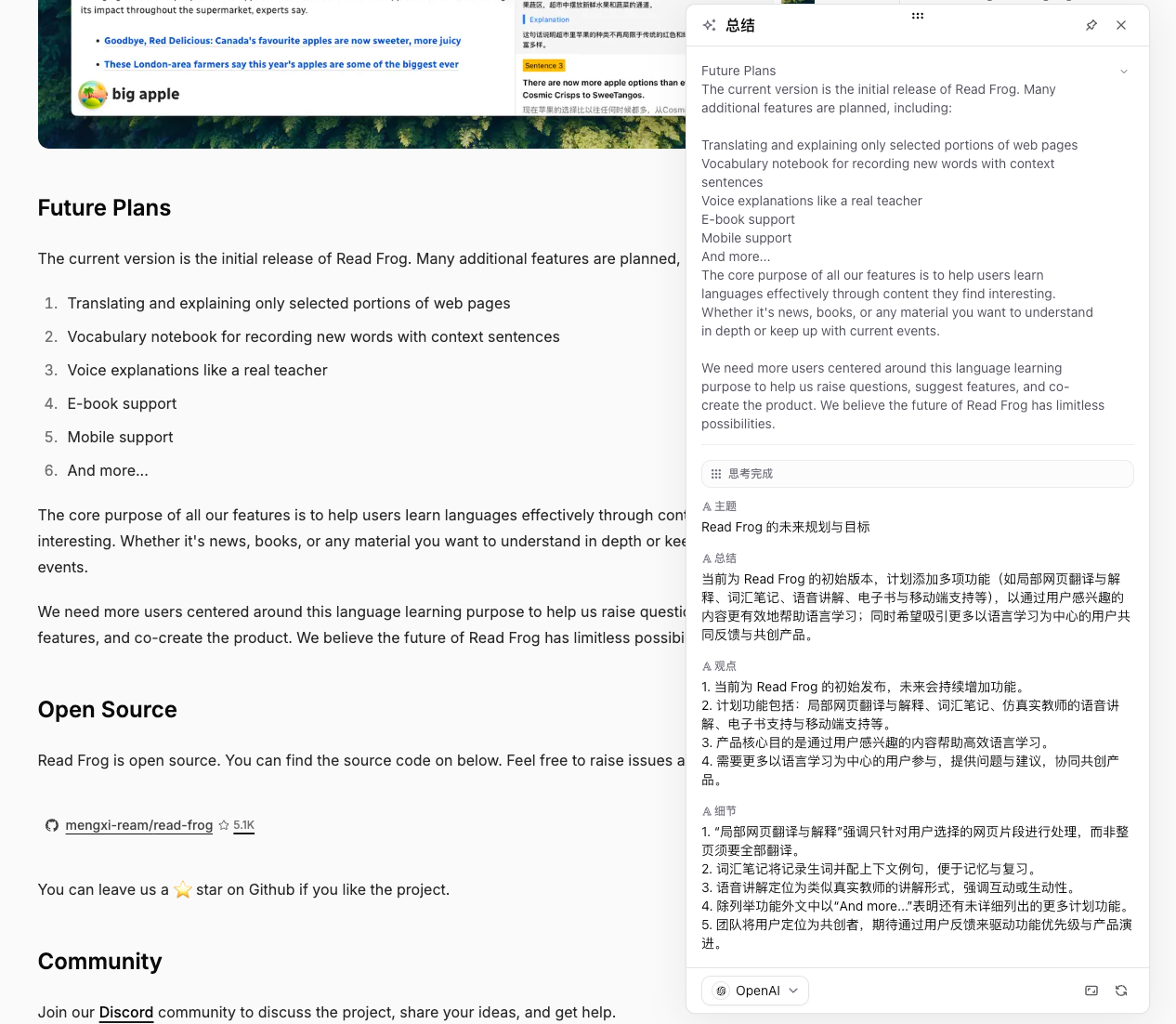
| 欄位名 | 字段類型 | 描述 |
|---|---|---|
| 主題 | 文字 | 概括 {{selection}} 所涉及內容的核心主題。 |
| 總結 | 文字 | 用一句話概括 {{selection}} 的核心意義。 |
| 觀點 | 文字 | 提煉與 {{selection}} 最相關的 3–5 個關鍵觀點,使用 \r\n 分隔。 |
| 細節 | 文字 | 列出容易被忽略但對理解 {{selection}} 有幫助的重要資訊點。 |
這樣你馬上就能得到一個適合文章、文件、教學場景的可重複使用閱讀助手。
實用建議
- 先把輸出字段做少,字段越少越穩定。
- 系統提示詞 負責約束模型,提供範例,提示詞 負責目前輸入格式。
- 如果結果不穩定,先刪欄位、簡化要求,再繼續加複雜規則。
- 字典場景優先選擇單字或片語,不要一上來就選整句。
故障排除
AI 指令存在但運作不了
先檢查這個AI 指令綁定的提供者是否已啟用,以及模型是否支援結構化輸出。
沒有保持到筆記庫的按鈕
這部分受 Beta Experience 和 Notebase beta 權限控制,沒有開啟或帳號沒權限時不會顯示。